
So your database is/was designed in a way that exact duplicate records could be inserted with no way to uniquely identify each row. Now that you need to delete duplicate rows you can do one of two things:
Schema:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| CREATE TABLE #STUDENTS | |
| ( | |
| FirstNames VARCHAR(50) NOT NULL, | |
| Surname VARCHAR(50) NOT NULL | |
| ); | |
| INSERT INTO #STUDENTS | |
| ( | |
| FirstNames, | |
| Surname | |
| ) | |
| VALUES | |
| ('John', 'Smith'), | |
| ('Matt', 'Maloon'), | |
| ('Justin', 'Smith'), | |
| ('Sam', 'Kind'), | |
| ('John', 'Smith'), | |
| ('Karl', 'Daniels'), | |
| ('Janette', 'Daniels'); |
Solution 1:
One way to do this is by inserting the data into a temp table, removing the data from the source table and re-insert it back.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| SELECT DISTINCT | |
| FirstNames, | |
| Surname | |
| INTO #STUDENTS_TEMP | |
| FROM #STUDENTS; | |
| DELETE FROM #STUDENTS; | |
| INSERT INTO #STUDENTS | |
| ( | |
| FirstNames, | |
| Surname | |
| ) | |
| SELECT FirstNames, | |
| Surname | |
| FROM #STUDENTS_TEMP; |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| (6 rows affected) -> Copy distinct items from #STUDENTS into #STUDENTS_TEMP | |
| (7 rows affected) -> Delete all records out of #STUDENTS | |
| (6 rows affected) -> Copy all items from #STUDENTS_TEMP into #STUDENTS |
Solution 2:
Using the ROW_NUMBER() function works great for deleting duplicate rows. Here’s an example to show how the ROW_NUMBER() function works and what to expect.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| WITH CTE | |
| AS (SELECT FirstNames, | |
| Surname, | |
| ROW_NUMBER() OVER (PARTITION BY FirstNames, Surname ORDER BY FirstNames, Surname) AS RowNum | |
| FROM #STUDENTS) | |
| SELECT CTE.FirstNames, | |
| CTE.Surname, | |
| CTE.RowNum | |
| FROM CTE; |
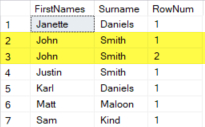
Now to delete the duplicate rows change the query to:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| WITH CTE | |
| AS (SELECT FirstNames, | |
| Surname, | |
| ROW_NUMBER() OVER (PARTITION BY FirstNames, Surname ORDER BY FirstNames, Surname) AS RowNum | |
| FROM #STUDENTS) | |
| DELETE FROM CTE | |
| WHERE CTE.RowNum > 1; |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| (1 row affected) -> Deleting the single duplicate record from the #STUDENTS table |
Hope this helps.
